這個 Lab 將練習如何使用 DQS Cleansing Transformation ,以及如何使用 DQS 比對原則知識庫進行重複資料的清除。
建立測試資料
首先我們要為 identity mapping 和 de-duplication 建立一個測試資料。這份資料包含二個版本:淨版和髒版。
Create CustomersClean
我們由 AdventureWorksDW2012.dbo.DimCustomer 中取得一份淨版的測試資料。
--create table CREATE TABLE dbo.CustomersClean ( CustomerKey INT NOT NULL PRIMARY KEY, FullName NVARCHAR(200) NULL, StreetAddress NVARCHAR(200) NULL ); --populate stage data INSERT INTO dbo.CustomersClean(CustomerKey, FullName, StreetAddress) SELECT CustomerKey, FirstName + ' ' + LastName AS FullName, AddressLine1 AS StreetAddress FROM AdventureWorksDW2012.dbo.DimCustomer WHERE CustomerKey % 10 = 0;
Create CustomersDirty
另外也建立一個髒版的測試資料,它與淨版的測試資料,只是多個二個欄位,且欄位值暫時都是空的。
- Updated field will be used by the query that makes the data dirty.
- CleanCustomerKey field will be used with the customer key from the clean table after identity mapping.
--create table CREATE TABLE dbo.CustomersDirty ( CustomerKey INT NOT NULL PRIMARY KEY, FullName NVARCHAR(200) NULL, StreetAddress NVARCHAR(200) NULL, Updated INT NULL, CleanCustomerKey INT NULL ); --populate stage data INSERT INTO dbo.CustomersDirty(CustomerKey, FullName, StreetAddress, Updated) SELECT CustomerKey * (-1) AS CustomerKey, FirstName + ' ' + LastName AS FullName, AddressLine1 AS StreetAddress, 0 AS Updated FROM AdventureWorksDW2012.dbo.DimCustomer WHERE CustomerKey % 10 = 0;
CustomersClean:

CustomersDirty:

Make the data dirty
使用以下 TSQL 語法去修改 CustomersDirty 中的資料,這些程式碼只會隨機且輕微的變更資料。 目的是要模擬真實世界中,資料彼此間的小小差異。
DECLARE @i AS INT = 0, @j AS INT = 0; WHILE (@i < 3) -- loop more times for more changes BEGIN SET @i += 1; SET @j = @i - 2; -- control here in which step you want to update -- only already updated rows WITH RandomNumbersCTE AS ( SELECT CustomerKey ,RAND(CHECKSUM(NEWID()) % 1000000000 + CustomerKey) AS RandomNumber1 ,RAND(CHECKSUM(NEWID()) % 1000000000 + CustomerKey) AS RandomNumber2 ,RAND(CHECKSUM(NEWID()) % 1000000000 + CustomerKey) AS RandomNumber3 ,FullName ,StreetAddress ,Updated FROM dbo.CustomersDirty ) UPDATE RandomNumbersCTE SET FullName = STUFF(FullName, CAST(CEILING(RandomNumber1 * LEN(FullName)) AS INT), 1, CHAR(CEILING(RandomNumber2 * 26) + 96)), StreetAddress = STUFF(StreetAddress, CAST(CEILING(RandomNumber1 * LEN(StreetAddress)) AS INT), 2, ''), Updated = Updated + 1 WHERE RAND(CHECKSUM(NEWID()) % 1000000000 - CustomerKey) < 0.17 AND Updated > @j; WITH RandomNumbersCTE AS ( SELECT CustomerKey ,RAND(CHECKSUM(NEWID()) % 1000000000 + CustomerKey) AS RandomNumber1 ,RAND(CHECKSUM(NEWID()) % 1000000000 + CustomerKey) AS RandomNumber2 ,RAND(CHECKSUM(NEWID()) % 1000000000 + CustomerKey) AS RandomNumber3 ,FullName ,StreetAddress ,Updated FROM dbo.CustomersDirty ) UPDATE RandomNumbersCTE SET FullName =STUFF(FullName, CAST(CEILING(RandomNumber1 * LEN(FullName)) AS INT), 0, CHAR(CEILING(RandomNumber2 * 26) + 96)), StreetAddress = STUFF(StreetAddress, CAST(CEILING(RandomNumber1 * LEN(StreetAddress)) AS INT), 2, CHAR(CEILING(RandomNumber2 * 26) + 96) + CHAR(CEILING(RandomNumber3 * 26) + 96)), Updated = Updated + 1 WHERE RAND(CHECKSUM(NEWID()) % 1000000000 - CustomerKey) < 0.17 AND Updated > @j; WITH RandomNumbersCTE AS ( SELECT CustomerKey ,RAND(CHECKSUM(NEWID()) % 1000000000 + CustomerKey) AS RandomNumber1 ,RAND(CHECKSUM(NEWID()) % 1000000000 + CustomerKey) AS RandomNumber2 ,RAND(CHECKSUM(NEWID()) % 1000000000 + CustomerKey) AS RandomNumber3 ,FullName ,StreetAddress ,Updated FROM dbo.CustomersDirty ) UPDATE RandomNumbersCTE SET FullName =STUFF(FullName, CAST(CEILING(RandomNumber1 * LEN(FullName)) AS INT), 1, ''), StreetAddress = STUFF(StreetAddress, CAST(CEILING(RandomNumber1 * LEN(StreetAddress)) AS INT), 0, CHAR(CEILING(RandomNumber2 * 26) + 96) + CHAR(CEILING(RandomNumber3 * 26) + 96)), Updated = Updated + 1 WHERE RAND(CHECKSUM(NEWID()) % 1000000000 - CustomerKey) < 0.16 AND Updated > @j; END;
經由以上的算法,將隨機更新 FullName 或 StreetAddress 欄位,且每更新一次, Updated 欄位值會加1.
以下二圖是隨機選取3筆記錄,分別是更新前與更新後的比較:

Check the dirty data
你可以使用以下 TSQL 檢查 CustomersDirty 中的資料。
SELECT 1.0 * (SELECT Count(1) FROM CustomersDirty WHERE Updated>0) / (SELECT Count(1) FROM CustomersDirty) SELECT Top 10 C.CustomerKey, C.FullName ,D.FullName, C.StreetAddress, D.StreetAddress, D.Updated, CleanCustomerKey FROM dbo.CustomersClean AS C INNER JOIN dbo.CustomersDirty AS D ON C.CustomerKey = D.CustomerKey * (-1)
你會發覺,在 CustomersDirty 資料表中,總共大約有 40% 的資料被更改過。

Setting a row to be corrected
我們額外更新一筆特定的資料,這筆資料列將在後面的練習中,使用 DQS Cleansing Transformation 來修正。
UPDATE dbo.CustomersDirty SET FullName = N'Jacquelyn Suarez', StreetAddress = N'7800 Corrinne Ct.', Updated=1 WHERE CustomerKey = -11010;

Use the DQS Cleansing Transformation
在進行比對前我們必須對資料先進行清理,這樣子才能提升比對的品質。本節將使用 SSIS 封裝,透過 DQS Cleansing Transformation 來清理資料。
建立封裝,執行資料清理
我們將在這個封裝中,先使用 DQS Cleansing Transformation 對 CustomerDirty 執行資料清理,以便產生一正較為正確的清單。 再將清理結果透過 Lookup Transfermation 與 CustomerClean 做明確比對。
清理的意思是說,只要符合知識庫中的原則,仍然視為相同的資料,以免被判定成不相同資料。 例如我們在知識庫中的 StreetAddress 定義域,已經設定了一個「以詞彙為主的關聯」,會將「Ct.」轉換成「Court」。 也就是說 DQS Cleansing Transformation 會先將來源資料依據知識庫原則轉換後再輸出。

新增專案與設定連接管理員
Drag a Data Flow Task .
New an OLEDB Connection, configure the connection to DQS_STAGING_DATA .
New an DQS Connection, configure the connection to Data Quqlity Server .

設定資料來源
Add an OLEDB Source . (named CustomersDirty)


設定 DQS Cleansing Transformation
Drag a DQS Cleansing Transformation . (named Cleanse StreetAddress)
Connect it to the CustomersDirty data source with the normal data flow (gray arrow).
In the DQS Cleansing Transformation Editor, configure the following setting.
設定 DQS 及 KB

將 StreetAddress 欄位對應到 StreetAddress 定義域。

在[進階]頁籤中,勾選[信賴]和[原因]選項。

設定 Lookup Transformation
Drag a Lookup Transformation , (named Exact Matches)
- 這個查閱轉換會將來源資料(CustomersDirty)與 CustomersClean 做明確比對。
- 在編輯器的在[連接]視窗中,設定資料來源的連接,連接到 DQS_STAGING_DATA.dbo.CustomersClean
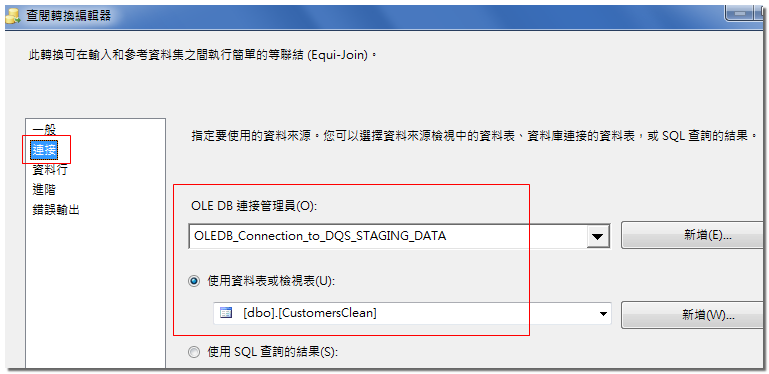
- 在[資料行]視窗中,設定輸入資料與查閱資料要比對的欄位,並勾選 CustomerKey 當做回傳欄位。

- 在[查閱作業]欄位中,選擇[取代'CleanCustomerKey'],並將[輸出]命名為CleanCustomerKey。
- 在[一般]視窗中,將查閱不到的資料導向[無相符合結果輸出]。

設定 Multicast Transformation
放置二個 Multicast Transformation ,分別用來接收查詢比對的結果。
儲存比對結果
1. 先在 DQS_STAGING_DATA 資料庫中,建立二個資料表。二者結構相同,將用來儲存比對結果。
CREATE TABLE dbo.CustomersDirtyMatch ( CustomerKey INT NOT NULL PRIMARY KEY, FullName NVARCHAR(200) NULL, StreetAddress_Source NVARCHAR(200) NULL, StreetAddress NVARCHAR(200) NULL, StreetAddress_Status NVARCHAR(100) NULL, StreetAddress_Confidence NVARCHAR(100) NULL, StreetAddress_Reason NVARCHAR(4000) NULL, Updated INT NULL, CleanCustomerKey INT NULL, Record_Status NVARCHAR(100) NULL ); CREATE TABLE dbo.CustomersDirtyNoMatch ( CustomerKey INT NOT NULL PRIMARY KEY, FullName NVARCHAR(200) NULL, StreetAddress_Source NVARCHAR(200) NULL, StreetAddress NVARCHAR(200) NULL, StreetAddress_Status NVARCHAR(100) NULL, StreetAddress_Confidence NVARCHAR(100) NULL, StreetAddress_Reason NVARCHAR(4000) NULL, Updated INT NULL, CleanCustomerKey INT NULL, Record_Status NVARCHAR(100) NULL );
2. 加入 OLE DB Destination , (named CustomerDirtyMatch)

3. 加入 OLE DB Destination , (named CustomerDirtyNoMatch)
執行 SSIS 封裝

檢查 CustomersDirtyMatch 和 CustomersDirtyNoMatch 中的資料。
你可以在 CustomersDirtyMatch 中找到 CustomerKey=-11010 這筆資料,且 StreetAddress 也已修正成「7800 Corrinne Court」。

Use DQS Matching
現在我們要使用 DQS 來進行資料比對,也就是要進行重複資料刪除。
建立比對資料集
完成以上練習,你還記得以下的資料表嗎?
- CustomerClean:原始的淨版資料。(records:1849)
- CustomerNoMatch:經由 Lookup Transformation 沒有被比對到的結果。(records:784)
我們建一個 View 來 Union 這二個資料。(records:2633)
CREATE VIEW dbo.vCustomersDQSMatch AS SELECT CustomerKey, FullName, StreetAddress FROM dbo.CustomersClean UNION SELECT CustomerKey, FullName, StreetAddress FROM dbo.CustomersDirtyNoMatch;
所以這個 View 共有 2633 筆資料,其中會有 784 筆是重複的,但是這些重複的資料與淨版資料實際上又存在些微的差異。 底下 Lab 就是要練習,如何使用 DQS 來刪除重複資料。
建立 KB
新增知識庫
新增一個知識庫:KB for Customers Matching

設定 data source

設定 domain
| 定義域名稱 | 資料類型 | 使用前置值 | 字串標準化 | 啟用拼字檢查 | 停用語法錯誤演算法 | 輸出格式 | 語言 |
|---|---|---|---|---|---|---|---|
| FullName | String | V | V | V | 無 | 英文 | |
| StreetAddress | String | V | V | V | 無 | 英文 |

設定 composite domain


建立比對原則
加入比對原則(Matching Rule)

加入新的定義域項目(Domain Element)

設定加權值(Weight)

啟對比對
在比對規則執行完成後,你可以在下方看到比對結果。

建立比對原則2
你可以建立其他的比對原則,以便對資料進行更多的比對測試。 例如下面這個例子對 FullName 定義域設定 40% 權重,StreetAddress 定義域設定 60% 。



啟動比對與檢視比對結果


發行知識庫
按下[完成]


建立 Matching Project
新增 DQS 專案
新增一個 DQS 專案:DQS Matching Project,其活動選項必須選擇「比對」。
- 知識庫:使用前面發行的KB for Customers Matching。
- 活動選項:必須選擇「比對」。

設定比對

執行比對

匯出比對結果
在匯出的內容中,包含二個結果。

- 比對結果:用來記錄比對的結果。

- 生存結果:用來記錄刪除重複記錄後的清單。(Survivorship Result)

沒有留言:
張貼留言