以下探討幾種不同類型的陳述式與查詢效能的關連。
使用 串接查詢條件
寫程式常會提供使用者查詢資料的介面,以取得使用者輸入的查詢條件,再將查詢條件串接成 TSQL。可是針對使用者沒輸入的欄位,我們總希望可以回傳所有資料,所以底下是我們常用的串接方法:
SELECT UserID FROM tblUser WHERE 1=1 AND ( UserName=@UserName OR @UserName='' ) ...
底下是這個陳述式的執行計畫,可以發覺,即使我們針對 UserName 欄位設定了索引,執行計畫卻沒有使用 Seek .
![]()
這是因為 @UserName='' 根本就沒有運用到索引,所以只能進行 Scan ,如果改成以下的 TSQL ,效能就可以立即提升。所以若要串接查詢條件還是得勤勞一點,如果使用者沒有輸入的欄位,就不要出現在 WHERE 條件中比較好。
SELECT UserID FROM tblUser WHERE 1=1 AND (UserName=@UserName)
![]()
注意
如果在 SP 中使用 WHERE UserName=@UserName ,若 @UserName 是 SP 的參數,因為此時這個變收是個不確定值,所以還是會使用 scan 運算。這個就是參數探測(Parameter Sniffing )問題造成的。如果要避免這個問題,可以使用區域變數取代,這樣才會使用 seek 運算。如:
DECLARE @LocalUserName nvarchar(20); SET @LocalUserName = @UserName SELECT UserID FROM tblUser WHERE UserName = @LocalUserName
使用「查詢參數」(Search Arguments, SARGs)
A search argument (SARG) is a filter expression that is used to limit the number of rows returned by a query and that can use an index seek operation that substantially improves the performance of the query.
並不是所有的 filter expression 都是 SARG ,例如:LEFT(Name, 1) = 'A' 或者 MONTH(OrderDate) = 6 ,這類經過額外運算處理的欄位都不算合法的 SARG。如果一個查詢中沒有合法的 SARG ,那麼查詢將採用 index scan 或 table scan 。
Select COUNT(1) From Orders WHERE YEAR(OrderDate)=1997

Select COUNT(1) From Orders WHERE OrderDate between '1997/1/1' and '1997/12/31 23:59:59'

使用 Joins
- To optimize queries, one of the first basic strategies is to minimize the number of join clauses used.
- Another consideration is that outer joins incur more cost than inner joins because of the extra work needed to find the unmatched rows.
相較於「子查詢 (Subquery)」,若能用 JOIN 完成的查詢,一般會比較建議使用後者。原因除了 JOIN 的語法較容易理解外,在多數的情況下,JOIN 的效能也會比子查詢較佳;但這並非絕對,也有的情況可能剛好相反。
使用 Sub Query
子查詢有分獨立子查詢(Uncorrelated Subqueries)和關連子查詢(Correlated Subqueries),不管哪一種子查詢都會引響效態。如果是獨立子查詢,其對效態引響還比較小,因為它只會執行一次。但是如果是關連子查詢,那就要非常小心使用,它隨著資料量的成長,效能會下降的非常快。
SELECT p.ProductID, p.ProductName, p.UnitPrice FROM Products AS p WHERE p.UnitPrice > ( SELECT AVG(P2.UnitPrice) FROM Products P2)
SELECT p.ProductID, p.ProductName, p.UnitPrice FROM Products AS p WHERE Exists ( SELECT ProductID FROM OrderDetails OD WHERE OD.ProductID = P.ProductID )
子查詢調校範例
SELECT OrderID,OrderDate, (Select Top(1) UnitPrice FROM OrderDetails OD WHERE OD.OrderID=O.OrderID ORDER BY Quantity) as UnitPrice, (Select Top(1) Quantity FROM OrderDetails OD WHERE OD.OrderID=O.OrderIDORDER BY Quantity) as Quantity FROM Orders O WHERE OrderID=10256

SELECT OrderID,OrderDate,A.* FROM Orders O OUTER APPLY ( Select Top(1) UnitPrice,Quantity FROM OrderDetails OD WHERE OD.OrderID=O.OrderID ORDER BY Quantity ) as A WHERE OrderID=10256

WITH A as ( SELECT O.OrderID, O.OrderDate, OD.UnitPrice, OD.Quantity, ROW_NUMBER() OVER (PARTITION BY O.OrderID ORDER BY Quantity DESC) as RowNum FROM OrderDetails OD INNER JOIN Orders O ON O.OrderID=OD.OrderID WHERE O.OrderID=10256 ) SELECT * FROM A WHERE ROwNum=1

使用 Scalar UDFs
Scalar UDFs是一種很常用的自訂函式類型,但不幸地,它也會降底執行效率。原因是這種函式無法被最佳化器擴展和最佳化到主要的查詢計畫中。執行計畫只會叫用這個函式,不會最佳化,也不會將它列入執行成本統計之中。
SELECT OrderID, OrderDate, dbo.fuGetEmpName(1) FROM Orders

上面範例使用 UDF ,但由執行計畫中卻都看不到任何 Employees 資料表的參考。
下面範例改採內嵌關連子查詢,可以發覺,雖然執行成本的數據看似較大,但是整體執行時間卻比較快。這是因為執行計畫可以連同內嵌關連子查詢一起做最佳化處理,所以執行效率會比較好。
SELECT OrderID, OrderDate, ISNULL( ( SELECT FirstName + ' ' + LastName FROM Employees WHERE EmployeeID = O.OrderID ), 'NOT FOUND') FROM Orders O

使用 Table-Valued UDFs
Table-Valued 的 UDFs 共有三種型態,其中二種是使用 TSQL 撰寫,另一種是 CLR 語言。
- T-SQL inline table-valued UDF
- T-SQL multistatement table-valued UDF
- CLR table-valued UDF
這三種 UDF 的行為各不相同:
inline t-v UDF
使用內嵌資料表值函式,它就像使用一個可以接受參數的view,最佳化工具可處理這類型自訂函式。

mulitstatement t-v UDF
使用多陳述式資料表值函式,它就像使用預存程序,然後產生暂存資料表給外部查詢使用。這種函式必須先被完全執行完畢,才能將結果提供給外部查詢使用。也就是說,如果這個函式必須回傳一百萬筆資料,整個查詢作業就要先等這一百萬筆資料處理完之後才會開始。
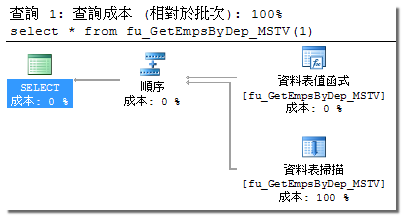
CLR t-v UDF
待。。。
使用 Cursors
使用 Cursor 會大大的降低執行效率,因為在 Cursor 迴圈中的 FETCH 陳述式,每次執行時就像是執行一次 SELECT 陳述式,而且還不能像 SELECT 陳述式一樣可以被最佳化。
You should try to rewrite cursor logic into one or more set-based statements (SELECT, INSERT, UPDATE, DELETE, or MERGE). If you cannot convert the cursor logic to a set-based statement, consider implementing the logic using a CLR stored procedure ora table-valued UDF instead (depending on the functionality you need).

沒有留言:
張貼留言