分割資料表(Partition Table)就如同資料表,只是在分割資料表中的資料會被分割成數個分割區(Partition)。 你可以將分割資料表建立在特定的檔案群組上,則所有分割區都會使用同一個檔案群組。 當然你也可以將分割資料表建立在特定的分割配置(Partition Scheme)上,則每個分割區都會使用不同的檔案群組,藉此提升存取效能。
只有 SQL Server Enterprise、Developer 和 Evaluation 版本上才可使用資料分割資料表和索引。
資料分割可以套用在資料表或索引,建立的步驟如下:
- 建立資料分割所需的的檔案群組。
- 建立資料分割函數(Partition Function)。
- 建立資料分割配置(Partition Scheme)。
- 使用資料分割配置建立資料表或索引。
建立檔案群組
如果你希望分割資料表使用不同的檔案群組,那麼你就必須先建立檔案群組。
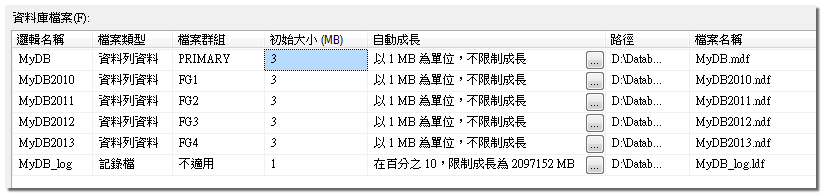
CREATE DATABASE [MyDB] ON PRIMARY ( NAME = N'MyDB', FILENAME = N'D:\Database\MyDB.mdf' , SIZE = 3072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ), FILEGROUP [FG1] ( NAME = N'MyDB2010', FILENAME = N'D:\Database\MyDB2010.ndf' , SIZE = 3072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ), FILEGROUP [FG2] ( NAME = N'MyDB2011', FILENAME = N'D:\Database\MyDB2011.ndf' , SIZE = 3072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ), FILEGROUP [FG3] ( NAME = N'MyDB2012', FILENAME = N'D:\Database\MyDB2012.ndf' , SIZE = 3072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ), FILEGROUP [FG4] ( NAME = N'MyDB2013', FILENAME = N'D:\Database\MyDB2013.ndf' , SIZE = 3072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'MyDB_log', FILENAME = N'D:\Database\MyDB_log.ldf' , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%) GO


建立分割函數(Partition Functions)
要建立分割資料表或分割索引的第一步驟就使用 CREATE PARTITION FUNCTION 建立分割函式。 分割函式會產生一個數值清單,用來定義每個 partition 的臨界值。
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type ) AS RANGE [ LEFT | RIGHT ] FOR VALUES ( [ boundary_value [ ,...n ] ] )
參數說明:
- input_parameter_type:用來分割的欄位的資料型別
- boundary_value:定義每個 partition 的臨界值。
- ,...n :
每個數字表示一個 partition , 在 SQL2008 最大可建立 1000 個 partition ;在 SQL2012 最大可建立 15000 個 partition 。 - LEFT | RIGHT :
用來表示間隔數值是屬於左區段還是右區段
範例一
CREATE PARTITION FUNCTION PF(INT)
AS RANGE LEFT
FOR VALUES (10, 20, 30);
/*
這個範例使用三個 int 型別的值來間隔分割區。
10 20 30
r1 ↓ r2 ↓ r3 ↓ r4
----------。----------。----------。----------
使用 LEFT 宣告,表示間隔值本身包含在左邊區間,所以四個區間的範圍如下:
PartitionNumber Partition Range
=============== ==================
1 range1 <= 10
2 10 < range2 <= 20
3 20 < range3 <= 30
4 30 < range4
*/
範例二
CREATE PARTITION FUNCTION P_Func(datetime)
AS RANGE RIGHT
FOR VALUES ('2011/01/01', '2012/01/01', '2013/01/01');
/*
這個範例使用三個 datetime 型別的值來間隔分割區。
2011/1/1 2012/1/1 2013/1/1
r1 ↓ r2 ↓ r3 ↓ r4
----------。----------。----------。----------
RIGHT 數字表示間隔值本身包含在右邊區間,所以四個區間的範圍如下:
PartitionNumber Partition Range
=============== ===================================
1 range1 < 2011/01/01
2 2011/01/01 <= range2 < 2012/01/01
3 2012/01/01 <= range3 < 2013/01/01
4 2013/01/01 <= range4
*/
建立分割配置(Partition Schemes)
要建立分割資料表或分割索引的第二步驟就使用 CREATE PARTITION SCHEME 建立分割配置。 分割配置是用來說明上一步驟定義的 partition 應該如何對應到 filegroups 。
使用不同的 filegroups 目的是希望將一個資料表中的資料分成數個分割區,分別儲存在不同裝置上。 例如將較舊的資料放在較慢但較便宜的設備,較新的資料則存放在較快但較貴的裝置上。
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )
參數說明:
- ALL:指定所有分割區都使用同一個檔案群組。
- TO ([ ,...n ] ):指定特定的檔案群組來存放 partition_function_name 所定義的分割。
範例三
這個範例建立一個分割配置,以對應到前一個範例(範例二)中所建立的每個 partition
--eg1:四個分割都使用不同的檔案群組 CREATE PARTITION SCHEME P_Scheme AS PARTITION P_Func TO (FG1, FG2, FG3, FG4); --eg2:四個分割只使用二個不同的檔案群組 CREATE PARTITION SCHEME P_Scheme AS PARTITION P_Func TO (FG1, FG2, FG1, FG2); --eg3:四個分割全使用[PRIMARY]這個檔案群組 CREATE PARTITION SCHEME P_Scheme AS PARTITION P_Func ALL TO ([PRIMARY]); --eg4:四個分割全使用[FG1]這個檔案群組 CREATE PARTITION SCHEME P_Scheme AS PARTITION P_Func ALL TO ([FG1]);
建立分割資料表(Partitioned Table)
建立分割資料表一樣是透過 CREATE TABLE 陳述式。 並使用 ON 子句決定資料分割區的儲存檔案群組。
範例四:建立分割資料表
這個範例使用分割配置 P_Scheme 建立一個分割資料表
CREATE TABLE Orders( [OrderID] [int] NOT NULL, [CustomerID] [nchar](5) NOT NULL, [EmployeeID] [int] NOT NULL, [OrderDate] [datetime] NOT NULL, [ShipName] [nvarchar](40) NULL, [ShipAddress] [nvarchar](60) NULL, ) ON P_Scheme(OrderDate)
範例五:建立分割索引
CREATE NonClustered INDEX IX_Orders_OrderID ON Orders ( OrderID )

測試範例
完成以上步驟之後,當資料新增到 Orders 資料表中的時候,不同年度的資料就會自動配置到不同的分割區。
insert Orders values('1','COMMI','8','2010-08-27','Comércio Mineiro','Av. dos Lusíadas, 23')
insert Orders values('2','CENTC','4','2011-07-18','Centro comercial Moctezuma','Sierras de Granada 9993')
insert Orders values('3','PICCO','8','2012-05-08','Piccolo und mehr','Geislweg 14')
insert Orders values('4','TRADH','1','2013-01-15','Tradiçao Hipermercados','Av. Inês de Castro, 414')
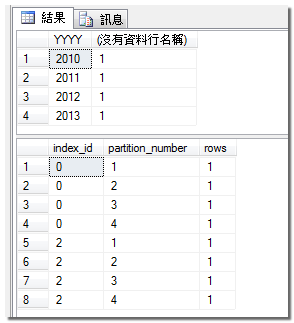
你可以檢查一下資料表中的資料,或者由 sys.partitions 檢視表中查詢每個 partition 的資料筆數。
SELECT YEAR(OrderDate) as YYYY , COUNT(1)
FROM Orders
GROUP BY YEAR(OrderDate)
SELECT index_id, partition_number, rows FROM sys.partitions
WHERE object_id = OBJECT_ID('Orders')
ORDER BY index_id, partition_number;
新增分割區
因為我們希望新增的分割區要放在不同的檔案群組,所以必須再建立一個檔案群組。 要不然,將新增的分割區放在舊有的檔案群組,就不用再建立一個檔案群組。
建立檔案群組
--在資料中新增檔案群組
ALTER DATABASE MyDB
ADD FILEGROUP FG5;
--加入一個檔案到 FG5 檔案群組
ALTER DATABASE MyDB
ADD FILE
(
NAME = N'MyDB2014',
FILENAME = 'D:\Database\MyDB2014.ndf',
SIZE = 3072KB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 51024KB
)
TO FILEGROUP FG5;
建立新分割區
ALTER PARTITION SCHEME P_Scheme NEXT USED [FG5]; --指定下個新分割區要使用的檔案群組
ALTER PARTITION FUNCTION P_Func() SPLIT RANGE ('2014/01/01'); --新分割區
--若要使用舊有的檔案群組也可以
ALTER PARTITION SCHEME P_Scheme NEXT USED [FG1];
ALTER PARTITION FUNCTION P_Func() SPLIT RANGE ('2015/01/01'); --新分割區
新增資料
insert Orders values('5','CENTC','2','2014-05-15','Centro comercial Moctezuma','Sierras de Granada 9993')

SWITCH 分割區
Partition Table 搭配 Switch 可將資料從原本的 Table 轉移到另一個 Table 。 因為這種作業只是變換系統目錄的指標,所以不管資料有多少筆,都是一瞬間就完成的事。
前一範例,我們建立一個新分割區,並對應到檔案群組 FG5 。 底下我們要示範,如何將一個 TABLE 中的資料,轉移到前面範例中的 Partition Table。 要執行 Switch 分割區,必須在同一個 FileGroup 底下的分割區才可以。 所以底下測試資料表,必須建立在 FG5 底下 。
建立要轉移的測試資料
CREATE TABLE Orders2014( [OrderID] [int] NOT NULL, [CustomerID] [nchar](5) NOT NULL, [EmployeeID] [int] NOT NULL, [OrderDate] [datetime] NOT NULL, [ShipName] [nvarchar](40) NULL, [ShipAddress] [nvarchar](60) NULL, ) ON [FG5] insert Orders2014 Select Top 100 OrderID, CustomerID, EmployeeID, DATEADD(YEAR,16,OrderDate), ShipName, ShipAddress From test..orders where year(OrderDate)=1998 order by NEWID()
來源資料必須和目標資料表相同結構
要轉移的資料,其結構也要和分割資料表相同,所以若有索引或條件約束等都必須先建立。 而且,特別要注意的是非叢集索引的設定,它必須將分割欄位加進 INCLUDE 欄位。 因為在已分割的資料表中它是自動完成的,但是在新的資料表並沒有,所以要加進 INCLUDE 欄位。
還有,分割資料表中的第5個分割區,限制資料的OrderDate必須大於等於2014/01/01,所以要轉移的資料也必須加入這個條件約束。
還有,目標資料分割必須存在,也必須是空的。
--建立索引 CREATE NonClustered INDEX IX_Orders_OrderID ON Orders2014 ( [OrderID] ) INCLUDE ([OrderDate]) --建立條件約束 ALTER TABLE Orders2014 ADD CHECK(OrderDate >= '2014/01/01');
執行轉移資料
現在可以進行分割區轉移了。
ALTER TABLE Orders2014 SWITCH TO Orders PARTITION 5; SELECT * FROM Orders2014; -- 轉移後,這個資料表就空掉了。


感謝VITO 大大用心的教學,很讚,可以出書了。
回覆刪除呵~~
回覆刪除這些內容, 大部份都來自書中, 或網路中.
只是個人的學習記錄而已