資料庫的索引,就像書本的索引資訊一樣,用來提升資料詢找的效率。 但是索引的建立,卻不是隨便的,也不是越多越好,正確的設定才可以真正提升 SQL Server 的執行效率。
本節目錄:
- 認識【叢集索引】與【非叢集索引】
- 如何使用語法建立、刪除、停用、啟用索引
- 重建索引與重組索引
- 索引設立原則
- 如何判斷Table中哪些欄位有建立索引
- 如何找出資料庫裡是否建立了多餘的索引
- 如何得知索引使用空間大小
- 如何得知索引使用次數
認識【叢集索引】與【非叢集索引】
索引
SQL Server 透過平衡樹(B-Tree)來建立索引,B-Tree 是由一個根節點和 N 個中間級節點加 N 個葉級節點組成。
在 SQL SERVER 裏面資料空間都是以頁(Page)為一個單位,存放索引的空間就叫索引頁,存放資料的空間就叫資料頁。 你可以把頁想像成就像硬碟裏的"磁區",不管資料頁或者是索引頁,一個頁的大小就是8K,實際上可以存的大小是 8060 byte。
例如,若有個Table共有100筆資料,若我們要針對一個 char(60) 欄位建立索引,則索引行共需要100 x 60 = 6k byte的大小。 這個大小可以塞到同一個頁當中(因為一頁有8K的空間)。 這一頁裏面,會包含根級和葉級的索引行。
當這個 Table 有 135 筆資料時,則索引共需要 135 x 60 = 8100 byte的大小。 這時候一頁 (8060 byte) 就塞不進去這麼多索引了。 此時會需要三個頁,為什麼? 因為第一頁要放 135 筆資料中的前半部索引,第二頁放 135 筆中的後半部索引,而第三頁只有二行索引,分別指向第一頁及第二頁。(此時沒有中間級的索引頁)。 以這個例子來看,一個頁最多可以存放 134 行,所以就可以指向 134 個葉級子頁,因此共可以索引134 x 134 = 17956 個資料行。由此可知,如果資料行數大於17956,則會有中間層出現。 當中間層出現時,則可以存放134 x 134 x 134 = 2406104 行索引。
索引的維護工作通常發生在Insert的時候。 當Insert一筆資料時,同時也得將資料插到正確的索引頁中,而且索引頁中的資料還要進行重新排序才行。 所以,若一個table建立了三個索引,insert一次就要多出 3 個寫入索引的動作。 另外,當一個葉級的索引頁空間沒了,SQL Server 就會執行頁面分割(page split)的動作。 該動作會將原先索引頁中的一半索引行copy到新的索引頁中。
SQL 提供二種索引:【叢集索引】與【非叢集索引】,這二種索引的存放都是採用 B-Tree 架構。 如果沒有任何索引,資料直接以 Heap 架構存放。
叢集索引(Clustered Index)
當資料表設定了「叢集索引」,那麼該資料表中的「實體資料列」的順序就會依據叢集索引鍵的值做排列。 所以任何一個資料表最多就只能有一個「叢集索引」,因為實體資料列的排列順序不可能有多種。 在 SQL Server ,Table的主索鍵(PK),其屬性預設為「叢集索引」且是唯一的(Unique),若你要將別的索引設定為叢集索引,則必須先取消主索鍵的叢集屬性。
叢集索引不須要葉級的索引頁,葉級的索引頁就是實際的資料頁。找到葉級的索引就等於找到實際的資料頁了。 不過,要清楚的是,雖然實體資料列是以叢集索引做排序,但不表示實體資料列的物理順序(physical)也是相同的,因為資料頁不一定是放在連續的磁軌中。

叢集索引的特性:
- 每個資料表只能有 1 個叢集索引
- 每個資料表最多可以有 249 個非叢集索引
- 非叢集索引對應至 Row ID 或 Clustering Ke
- 每個索引最多可以包括 16 個欄位,不得超過 900 Bytes
- 叢集索引不可使用在包含 LOB 欄位(image/text/xml/max 型態,如 varchar(max)),非叢集索引則無此限制
線上索引 (ONLINE)
值得當使用 TSQL 的 CREATE INDEX 命令中,有一個選項叫 ONLINE ,預設值是 OFF。 開啟這個功能(ON),可以讓SQL Server 在創建叢集索引(也就是Insert)的同時還可以 SELECT 或 UPDATE 資料,且不會把整個資料表鎖死。
這個選項是 SQL Server 企業版才有的功能。
若一個資料表有叢集索引,則非叢集索引的索引值會存放叢集索引的Key值。 若一個資料表沒有叢集索引,則非叢集索引的索引值會存放 Heaper 的 RID (row identifier)。

最適合當叢集索引的欄位
- the most frequently queried foreign key column
- the most frequently searched date column
決定叢集索引欄位的考量
- 欄位數盡可能越少越好
- 欄位大小盡可能越少越好
- 常被用來 ORDER BY 或是 GROUP BY 的欄位
若索引鍵值常用於ORDER BY 與GROUP BY中時,因為實體資料已經排序好了,系統不會再進行排序的動作,因此會增加執行的速度。 - 常被用來 BETWEEN 查詢的欄位
因為實體資料是按照鍵值依序得存入硬碟中,若依 Between >= <= 等符號查詢時,當系統找到第一筆資料後,依序逐筆往下讀取,查詢的結果是連續性的範圍,則執行的速度也會提升。 - 被定義成IDENTITY欄位
- 連續性的範圍查詢結果
- 會用於JOIN指令中欄位建議加入,一般都是 foreign Key 欄位
不適合當叢集索引的欄位
- 更新頻率過高的欄位
因為Clustered Index每次更新時都會對實體資料進行排序,如果資料量較大的資料表,系統會在排序上會多花不少時間處理,所以並不建議以此類的欄位當索引鍵。 - 過多或過大的欄位所組成鍵值
因為過多或過大都會造成系統在進行排序時的負擔。 - 獨特性過高的欄位
因為實體資料是經過排序存入到硬碟中,若欄位中每筆記錄都沒甚麼順序性,則無法有效利用到此排序索引,例如,一個門市的銷售檔內,只以「稅別」當索引鍵,當查詢時若用到的是日期、商品或是公司來進行查詢時,都不會使用到Clustered-Index排序的功能,除此外也可能因一千萬筆的銷售資料中,只有一筆是免稅,其他都是含稅,導致無法有效的利用到排序。
非叢集索引(NonClustered Index)
每個資料表能建立多個 NonClustered-Index(最多249個非叢集索引),此類的索引單純存放著指標資料,而該指標所對應到的是 Clustered-Index 或是 Heaper 內實體資料所存放的位置。
一個資料表最多可以設定249個非叢集索引(書上沒有說為什麼是249這個數)。 非叢集索引必須依據葉級索引內的值才能找到實際的資料頁,存放在葉級索引裡的值有二個可能。
- 資料表有主鍵時,索引指向主鍵的索引。
- 如果資料表中沒有設主鍵,則指到資料頁的物理位置,也就是 Heaper 內實體資料所存放的位置。
下圖顯示單一資料分割中非叢集索引的結構。

如何使用語法建立、刪除、停用、啟用索引
- CREATE INDEX :建立索引
- ALTER INDEX :停用、啟用、重建、重組索引
- DROP INDEX :刪除索引
建立索引
建立索引陳述式: CREATE INDEX 。
定義
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> ( column [ ASC | DESC ] [ ,...n ] )
[ INCLUDE ( column_name [ ,...n ] ) ]
[ WHERE <filter_predicate> ]
- INCLUDE ( column_name[,..n] ) :設定要加入至非叢集索引的資料行。
- WHERE <filter_predicate> :在非叢集索引上設定篩選條件。
範例
這個範例使用 Price 欄位建立一個非叢集索引, 索引已篩選掉 Price=Null 的資料,同時將 ProductName 欄位加入到索引的內含資料行。
CREATE NONCLUSTERED INDEX [IX_ProductPrice] ON [Products] ( [Price] ASC ) INCLUDE ( [ProductName] ) WHERE Price IS NOT NULL
刪除、停用、啟用索引
刪除
DROP INDEX {IndexName} on {TableName}
停用
ALTER INDEX <index_name> ON <table_name> | <view_name> DISABLE
啟用
ALTER INDEX <index_name> ON <table_name> | <view_name>
管理主索引鍵
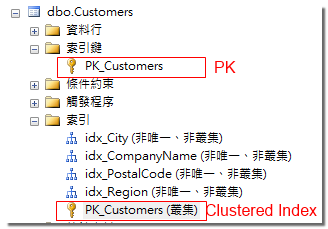
當建立「主索引鍵(Primary key, PK)」時,系統會同時自動建立一個相對應叢集索引。 因為主索引鍵是一種「條件約束」,這個條件約束將會限制重複的索引鍵值,並不是因為叢集索引的原故。
與「主索引鍵」相對應的叢集索引,受「主索引鍵」強制執行的原故,是不能獨立被刪除的。若要調整,你必須對條件約束下手:
--建立主索引鍵 ALTER TABLE Customers ADD CONSTRAINT PK_Customers PRIMARY KEY CLUSTERED ( CustomerID ASC ) --刪除主索引鍵 ALTER TABLE Customers DROP CONSTRAINT PK_Customers;
重建索引與重組索引
當資料進行新增、修改、刪除的時候,就會產生索引碎裂(index fragmentation)。 通常索引碎裂是以百分比來描述,當索引碎裂程度過高時(大於30%),索引的效率就會開始降低,為了避免這個問題發生,就必須進行索引重建(rebuild)或索引重組(reorganize)。
查詢碎裂情況
外部碎片 (External Fragmentation):
外部碎片主要發生於資料存放的索引頁 (Index Leaf Page) 不連續所造成,當有新的索引產生時,會先檢查索引頁中是否有空間可以進行存放,如果沒有時,就會產生一個新的索引頁,然後再將資料放入,因此也就造成索引存放不連續,當進行索引掃描 (Index Scan) 時,會造成讀寫頭過多的移動,造成 I/O 的浪費。
內部碎片 (Internal Fragmentation):
內部碎片主要發生在當填滿因素 (fill factor) 不為 0 或 100 %的時候,比如說設定填滿因素 (fill factor) 為 80%,剩下的20%就是內部碎片。
要執行索引重建前,可以使用 SELECT 指令搭配 sys.dm_db_index_physical_stats 這個動態管理函示(DMF, Dynamic Management Function) 來查詢資料庫中索引的碎裂狀態
SELECT CAST(OBJECT_NAME(OBJECT_ID) AS VARCHAR(20)) AS [TABLE NAME], Index_id, Index_type_desc, Avg_fragmentation_in_percent, Avg_page_space_used_in_percent FROM sys.dm_db_index_physical_stats(DB_ID(N'test'),NULL,NULL,NULL,'Detailed') WHERE index_id > 0 ORDER BY Avg_page_space_used_in_percent DESC

PS. DB_ID() 是系統內建的函式,在SQL2005之後,才允許使用函式當作另一個函式的參數。若要變更相容性層級,可參考下圖:

--查詢 SELECT compatibility_level FROM sys.databases WHERE name = 'test'; --變更 ALTER DATABASE test SET COMPATIBILITY_LEVEL = 90; -- SQL 2005
何時該索引重建或索引重組
索引重建或重組,都是用來重新建置索引,以減少索引碎裂情形,進而提高索引效能。至於何時該進行索引重建,又何時該進行索引重組,可參考以下建議:
索引重建的時機 (REBUILD)
- 檢查 External fragmentation 部分:當 avg_fragmentation_in_percent > 15
- 檢查 Internal fragmentation 部分:當 avg_page_space_used_in_percent < 60
索引重整的時機 (REORGANIZE)
- 檢查 External fragmentation 部分:當 10 < avg_fragmentation_in_percent < 15
- 檢查 Internal fragmentation 部分:當 60 < avg_page_space_used_in_percent < 75
也就是
- fragmentation 破碎率大於 15% 請重建;大於 10% 請重整。
- page_space_used 使用率小於 60% 請重建;小於 75% 請重整。
如何重建索引
使用資料庫主控台命令陳述式 (DBCC, Database Console Command )
| 指令 | 說明 |
|---|---|
| DBCC ShowConfig | 顯示指定資料表或檢視之資料與索引的片段資訊。 |
| DBCC DBReIndex | 重組指定資料表或檢視的索引。 |
| DBCC IndexDefrag | 在指定的資料庫中,重建資料表的一個或多個索引。 |
以上三個方法
- 皆為離線的操作工具。也就是當執行此項作業時,資料庫的使用者將無法使用相關的資料表。
- 適用SQL 2008,2005,但 MS 聲明往後版本不再支援,請使用 ALTER INDEX
使用 ALTER INDEX
索引重整 (REORGANIZE):
ALTER INDEX [PK_tblDocuments] ON [dbo].[tblDocuments] REORGANIZE WITH (FILLFACTOR = 100);
索引重建 (REBUILD):
ALTER INDEX [PK_tblDocuments] ON [dbo].[tblDocuments] REBUILD WITH (FILLFACTOR = 100);
PS:FILLFACTOR可以不指定,如果不指定時,系統會透過預設的 fill factor 進行。
查詢適合重建的索引
透過以下的查詢,可以快速方便的列出適合進行重建的索引
SELECT 'ALTER INDEX [' + ix.name + '] ON [' + s.name + '].[' + t.name + '] ' +
CASE
WHEN ps.avg_fragmentation_in_percent > 15 THEN 'REBUILD'
ELSE 'REORGANIZE'
END +
CASE
WHEN pc.partition_count > 1
THEN ' PARTITION = ' + CAST(ps.partition_number AS nvarchar(MAX))
ELSE ''
END,
avg_fragmentation_in_percent
FROM sys.indexes AS ix
INNER JOIN sys.tables t ON t.object_id = ix.object_id
INNER JOIN sys.schemas s ON t.schema_id = s.schema_id
INNER JOIN
(
SELECT object_id, index_id, avg_fragmentation_in_percent, partition_number
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL)
) ps ON t.object_id = ps.object_id AND ix.index_id = ps.index_id
INNER JOIN
(
SELECT object_id,index_id , COUNT(DISTINCT partition_number) AS partition_count
FROM sys.partitions
GROUP BY object_id, index_id
) pc ON t.object_id = pc.object_id AND ix.index_id = pc.index_id
WHERE
ps.avg_fragmentation_in_percent > 10
AND ix.name IS NOT NULL
索引設立原則
- 記得自行幫 Foreign Key 欄位建立索引,即使是很少被 JOIN 的資料表亦然。
- 替常被查詢或排序的欄位建立索引,如:常被當作 WHERE 子句條件的欄位。
- 用來建立索引的欄位,長度不宜過長,不要用超過 20 個位元組的欄位,如:地址。
- 不要替內容重複性高的欄位建立索引,如:性別;反之,若重複性低的欄位則適合建立索引,如:姓名。
- 不要替使用率低的欄位建立索引。
- 不宜替過多欄位建立索引,否則反而會影響到新增、修改、刪除的效能,尤其是以線上交易 (OLTP) 為主的網站資料庫。
- 若資料表存放的資料很少,就不必刻意建立索引。
- 若資料表存放的資料很少,就不必刻意建立索引。否則可能資料庫沿著索引樹狀結構去搜尋索引中的資料,反而比掃描整個資料表還慢。
- 若查詢時符合條件的資料很多,則透過「非叢集索引」搜尋的效能,可能反而不如整個資料表逐筆掃描。
- 建立「叢集索引」的欄位選擇至為重要,會影響到整個索引結構的效能。要用來建立「叢集索引」的欄位,務必選擇「整數」型別 (鍵值會較小)、唯一、不可為 NULL。
如何判斷Table中哪些欄位有建立索引
sp_helpindex
sp_helpindex 可以用查詢 Table 或 View 的索引相關資訊。 如果在查詢結果的 index_keys 欄位中,某個索引鍵值欄名稱後面有(-),就表示這個索引鍵值欄係以遞減方式排序。

sp_help
使用 sp_help 查詢某個資料表所得到的資訊,可以得到比使用 sp_helpindex 更多的資訊。
sys.index_columns
sys.index_columns 可用來查詢 Table 的索引欄位

如何得知索引使用空間大小
sp_spaceused 可用來顯示資料列的數目、保留的磁碟空間大小、資料所用的磁碟空間、索引檢視所用的磁碟空間,或顯示整個資料庫所保留和使用的磁碟空間。
--顯示資料庫大小 EXEC sp_spaceused @updateusage=N'true'; --顯示資料表大小 EXEC sp_spaceused 'TestTable';

如何得知索引使用次數
一個索引可能用途有三種:搜尋(Seek)、掃描(Scan)、查閱(Lookup)。 當 SQL 啟動後,索引的使用狀況變會持續進行統計,這些資訊可以經由 sys.dm_db_index_usage_stats 這個 DMV 來查閱得知。 統計值會一直累計,直到 SQL SERVER 被重新啟動後才會重置。
select * from sys.dm_db_index_usage_stats

欄位說明:
- user_seeks:這個索引被使用在 index seek 次數
- user_scans:這個索引被使用在 index scan 次數
- user_lookups:這個索引被使用在 index lookup 次數
- user_updates:索引更新次數
- last_user_seek:上一次執行 index seek 的時間
- last_user_scan:上一次執行 index scan 的時間
- last_user_lookup:上一次執行 index lookup 的時間
在查詢結果中,你應該關注的是:
- 若 user_seeks 或 user_scans 值都很低,表示這個索引很少在使用。
- 若 user_seeks 很低, user_scans 很高,表示這個索引不是一個好的索引,應該可以進一步重新規劃。
- 若 user_updates 很高,可以檢查看看,是否有不必要加入索引的欄位。
底下例子是針對 Customers 資料表,搭配 sys.indexes 的資訊,列出 Customers 資料表中各個索引的使用狀況。
SELECT OBJECT_NAME(I.object_id) AS table_name, I.name AS index_name, S.user_seeks, S.user_scans, S.user_lookups,I.type_desc, CASE WHEN last_user_seek is not null then last_user_seek WHEN last_user_scan is not null then last_user_scan else last_user_update END as user_time FROM sys.indexes AS I LEFT JOIN sys.dm_db_index_usage_stats AS S ON S.object_id = I.object_id AND S.index_id=I.index_id WHERE I.object_id = OBJECT_ID(N'Customers', N'U') ORDER BY user_time desc;

如何找出資料庫裡是否建立了多餘的索引
要找出多餘的索引,原則上就是參考上面提到的索引使用次數的值。如果太低則表示該索引可能是多餘的。 而 SQL Server 本身有提供許多現成的報表可供參考,你可以利用這報表來判斷。 詳細內容請參考保哥這篇文章:如何找出 SQL Server 2008 資料庫裡是否建立了多餘的索引

沒有留言:
張貼留言